Универсальный фаззер для грамматик
Этот текст - продолжение поста про фаззинг. Его я закончил на том, что было бы здорово на основе грамматики генерировать примеры для тестирования приложений.
Пожалуй самый известный пример это csmith. Фаззер генерирует синтаксически правильную программу на языке Си и с помощью тестируемого компилятора пытаются эту программу скомпилировать. С помощью csmith нашли семь десятков багов в gcc и пару сотен в LLVM.
Второй пример это sqlsmith. Принцип точно такой же как и у csmith, список багов
тоже не маленький - семь десятков.
sqlsmith и csmith имеют одну общую черту - генератор для каждого из них писали
отдельно. Писать свой генератор для синтаксиса каждого из демонов OpenBSD мне
совсем не хотелось. К тому же синтаксис мог со временем меняться и генератор
пришлось бы исправлять.
Ещё один пример это фаззер для CockroachDB. Эта СУБД имеет нестандартную реализацию SQL, поэтому sqlsmith им не подошёл. Грамматика SQL для CockroachDB описывается в формате YACC и они на основе этой грамматики сделали генератор SQL запросов и нашли с ним 82 бага. Из-за того, что генератор использует YACC формат он опять же не является универсальным для разных грамматик.
В OpenBSD для описания грамматики конфигов тоже используется YACC, на основе которого с помощью утилиты yacc генерируется парсер. Пример описания для yacc выглядит так:
%{
#include <stdio.h>
#include <string.h>
void yyerror(const char *str)
{
fprintf(stderr,"error: %s\n",str);
}
int yywrap()
{
return 1;
}
main()
{
yyparse();
}
%}
%token NUMBER TOKHEAT STATE TOKTARGET TOKTEMPERATURE
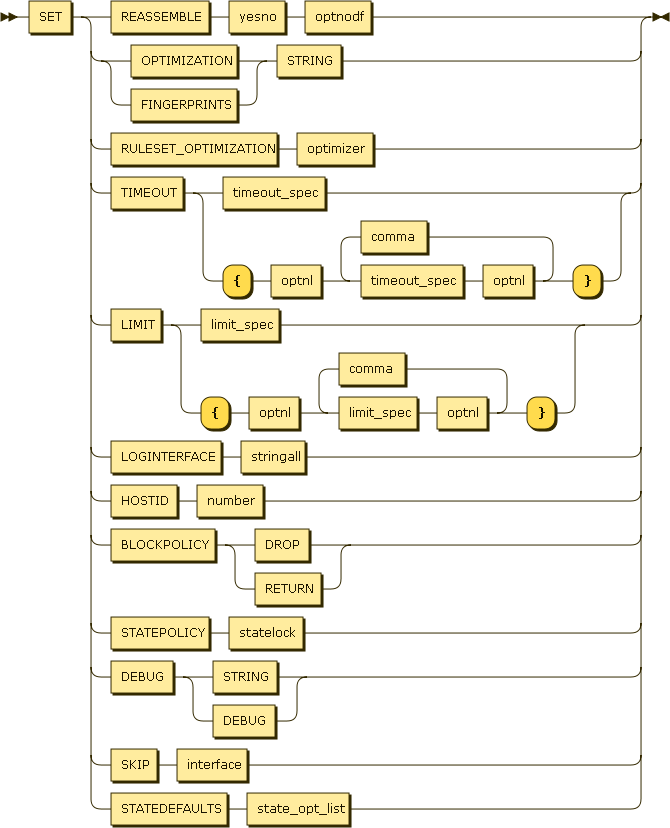
Мне нужно было YACC-описание преобразовать в более стандартный и читаемый формат, желательно независимый от языков программирования. Таким форматом является BNF - форма Бэкуса-Наура. BNF используется для описания синтаксиса языков программирования, протоколов и т.д. Вот так, например, выглядит описание небольшой части синтаксиса конфига пакетного фильтра в OpenBSD:
line = ( option | pf-rule |
antispoof-rule | queue-rule | anchor-rule |
anchor-close | load-anchor | table-rule | include )
option = "set" ( [ "timeout" ( timeout | "{" timeout-list "}" ) ] |
[ "ruleset-optimization" [ "none" | "basic" |
"profile" ] ] |
[ "optimization" [ "default" | "normal" | "high-latency" |
"satellite" | "aggressive" | "conservative" ] ]
[ "limit" ( limit-item | "{" limit-list "}" ) ] |
[ "loginterface" ( interface-name | "none" ) ] |
[ "block-policy" ( "drop" | "return" ) ] |
[ "state-policy" ( "if-bound" | "floating" ) ]
[ "state-defaults" state-opts ]
[ "fingerprints" filename ] |
[ "skip on" ifspec ] |
[ "debug" ( "emerg" | "alert" | "crit" | "err" |
"warning" | "notice" | "info" | "debug" ) ] |
[ "reassemble" ( "yes" | "no" ) [ "no-df" ] ] )
yacc не может преобразовать YACC-описание напрямую в BNF форму, но с ключом
-v можно преобразовать в описание, удобное для чтения, а потом сделав
небольшие преобразования получить описание в EBNF, расширенной BNF форме. EBNF
это как раз то, что мне и было нужно. Для чтения EBNF во многих языках есть
модули и сделать генератор не будет большой проблемой.
Приятный бонус использования EBNF это возможность нарисовать railroad диаграммы для грамматики:
Насколько эффективным получился мой генератор напишу в одном из следующих постов.
Если тема показалась интересной, то вот список статей на подобную тематику:
- Experiences with Model Inference Assisted Fuzzing
- Фаззер языков на основе грамматик LangFuzz
- Fuzzing with Code Fragments
- BlendFuzz: A Model-Based Framework for Fuzz Testing Programs with Grammatical Inputs
- Property-based тестирование с BNF
- Fuzzing with Code Fragments
- A sentence generator for testing parsers
- Grammar Based Unit Testing for Parsers
- Фаззеры для тестирования безопасности dharma и avalanch